Author :- Rishi Joshi
Now a day’s analytics industry is all about gaining the “Information” from the data. With the growth in the amount of data, that is too unstructured, it’s difficult to obtain the relevant information. But, technology has developed some powerful methods which can be used to mine through the data and fetch the information that we are looking for. One such technique in the field of text mining is Topic Modelling.
Contents :-
Introduction.
What is Topic Modeling?
How To Implement Topic Modeling?
What is Latent Dirichlet Allocation?
Hyper parameters in LDA.
Conclusion.
What is Topic Modeling :-
In machine learning, a topic model is a type of mathematical model for finding out the “topics” that are present in a collection of documents.
Topic Modeling is recognizing the words from the topic present in a document or corpus of data.
Topic modeling is an unsupervised approach of recognizing or extracting the topics by detecting the patterns like clustering algorithms which divides the data into different parts.

Figure-1:Topic Modeling
For example, consider the following set of documents as the corpus:
Document 1: I had a peanut butter sandwich for breakfast.
Document 2: I like to eat almonds, peanuts, and walnuts.
Document 3: My neighbor got a little dog yesterday.
Document 4: Cats and dogs are mortal enemies.
Document 5: You mustn’t feed peanuts to your dog.
The LDA model discovers the different topics that the documents represent and how much of each topic is present in a document. For example, LDA may produce the following results:
Topic 1: 30% peanuts, 15% almonds, 10% breakfast.
Topic 2: 20% dogs, 10% cats, 5% peanuts.
Documents 1 and 2: 100% Topic 1
Documents 3 and 4: 100% Topic 2
Document 5: 70% Topic 1, 30% Topic 2
How To Implement Topic Modeling :-
Many techniques are used to obtain topic models:-
LDA:- Latent Dirichlet Allocation, a widely used topic modeling technique and the TextRank process.
NNMF:- Nonnegative matrix factorization (NMF) has become a widely used tool for the analysis of high-dimensional data
LSA:- Latent Semantic Allocation is typically used as a dimension reduction or noise-reducing technique.
In this blog, we are going to use LDA for implementing topic modeling.
What is Latent Dirichlet Allocation :-
Latent Dirichlet Allocation is a very popular topic modeling technique to extract topics from a given corpus, here the term latent means hidden.
The LDA makes two key assumptions:-
The documents are a mixture of topics.
And Topics are a mixture of tokens(or words).
In Statistical language:-
The documents are known as the “probability distribution of topics”.
The Topics are the “probability distribution of words”.
The applications of LDA need not be restricted to Natural Language Processing.
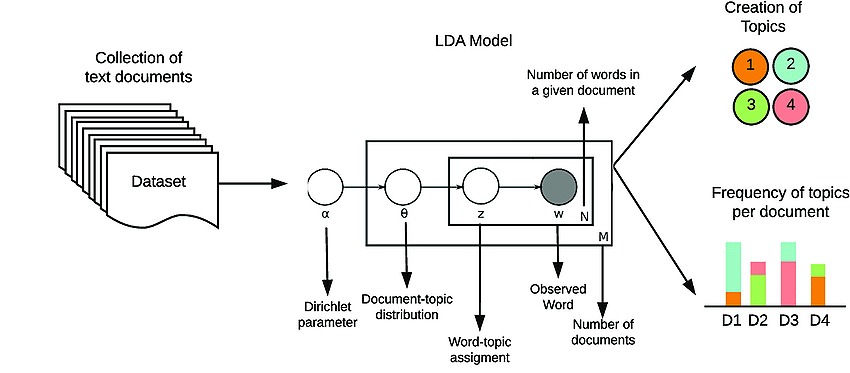
Figure-2: LDA Model
In the process of generating this document, first, a topic is selected from the document-topic distribution and later, from the selected topic, a word is selected from the multinomial topic-word distributions.

Figure-3: Document generation assumption
Hyper parameters in LDA :-
LDA has three hyperparameters :-
Assume there are ‘K’ topics across all of the documents.
Document-topic density factor ‘α’.
Topic-word density factor ‘β’.
The ‘K’ hyperparameter specifies the number of topics expected in the corpus of documents. Choosing a value for K is generally based on domain knowledge. The ‘α’ hyperparameter controls the number of topics expected in the document. The low value of ‘α’ is used to imply that a fewer number of topics in the mix is expected and vice-versa. The ‘β’ hyperparameter controls the distribution of words per topic. At lower values of ‘β’, the topics will likely have fewer words and vice-versa.

Fig 4 : LDA model representation
Extracting Topics using LDA in Python :-
Steps to implement LDA in python :-
1) Import Dataset and libraries :-
The data set I used is the 20Newsgroup data set. It is available under sklearn datasets.
# importing dataset
from sklearn.datasets import fetch_20newsgroups
train_data = fetch_20newsgroups(subset="train",shuffle=True)
test_data = fetch_20newsgroups(subset="test", shuffle=True)2) Preprocessing the raw text :-
This involves the following process :-
Tokenization: Split the text into sentences and the sentences into words. Lowercase the words and remove punctuation.
Words that have fewer than 3 characters are removed.
All stopwords are removed.
Words are lemmatized — words in third person are changed to first person and verbs in past and future tenses are changed into present.
Words are stemmed — words are reduced to their root form.
Code :-
def lemmatize_stemming(text):
return stemmer.stem(WordNetLemmatizer().lemmatize(text, pos='v'))
def preprocess(text):
result=[]
for token in gensim.utils.simple_preprocess(text):
if token not in gensim.parsing.preprocessing.STOPWORDS and len(token) > 3:
result.append(lemmatize_stemming(token))
return resultOutput :-

Figure-4
3) Converting text to bag of words :-
Prior to topic modelling, we convert the tokenized and lemmatized text to a bag of words- which you can think of as a dictionary where the key is the word and value is the number of times that word occurs in the entire corpus.
Code :-
dictionary = gensim.corpora.Dictionary(processed_docs)
bow_corpus = [dictionary.doc2bow(doc) for doc in processed_docs]The result look like:

Figure-5
4) Running LDA :-
This is actually quite simple as we can use the gensim LDA model. We need to specify how many topics are there in the data set. Lets say we start with 8 unique topics. Num of passes is the number of training passes over the document.
lda_model = gensim.models.LdaMulticore(bow_corpus,
num_topics=8,
id2word=dictionary,
passes=10,
workers=2) 5) Results :-

Figure- 6
Conclusion :-
Topic Modeling is being also used in other contexts like biology and blockchain etc. The application of LDA should not be restricted to Natural Language Processing. If you are reading this and thinking “but I’ve got a perfect use case, where I found something novel and robust from a corpus using LDA”, and you can share it with me, then please get in touch at the email address below.
コメント